该文章内容发布已经超过一年,请注意检查文章中内容是否过时。
[Google Paper] 面向云时代的应用开发新模式
本文翻译自发表在以下地址的论文:https://serviceweaver.dev/assets/docs/hotos23_vision_paper.pdf
原文作者(Authors): Sanjay Ghemawat, Robert Grandl, Srdjan Petrovic, Michael Whittaker, Parveen Patel, Ivan Posva, Amin Vahdat
转载或发布请遵循原文许可: Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for thirdparty components of this work must be honored. For all other uses, contact the owner/author(s). HOTOS ’23, June 22–24, 2023, Providence, RI, USA © 2023 Copyright held by the owner/author(s). ACM ISBN 979-8-4007-0195-5/23/06. https://doi.org/10.1145/3593856.3595909
摘要
在编写分布式应用程序时,传统的明智做法是将您的应用程序拆分为可以分别拉起的独立服务。这种方式的用意是好的,但像这样基于微服务的架构经常会适得其反,带来的挑战抵消了架构试图实现的好处。从根本上说,这是因为微服务将逻辑边界(代码的编写方式)与物理边界(代码的部署方式)混为一谈。在本文中,我们提出了一种不同的编程方法,将两者(代码编写与部署方式)分离以解决这些挑战。通过我们的方法,开发人员将他们的应用程序编写为逻辑上的单体,将有关如何分发和运行应用程序的决策放到一套自动化运行时 (runtime),并以原子方式部署应用程序。与当前的微服务开发模式相比,我们的原型应用最多可减少延迟 15 倍、成本最多减少了 9 倍。
ACM 参考格式: Sanjay Ghemawat, Robert Grandl, Srdjan Petrovic, Michael Whit-taker, Parveen Patel, Ivan Posva, Amin Vahdat. 2023. Towards Mod-ern Development of Cloud Applications. In Workshop on Hot Topics in Operating Systems (HOTOS ’23), June 22–24, 2023, Providence, RI, USA. ACM, New York, NY, USA, 8 pages. https://doi.org/10.1145/3593856.3595909
1 介绍
近年来,云计算出现了前所未有的增长。编写和部署可扩展到数百万用户的分布式应用程序从未如此简单,这在很大程度上归功于 Kubernetes [25] 等框架,[7, 18, 31, 33, 40, 60] 等消息传递解决方案,以及数据格式如 [5,6, 23, 30]。使用这些技术时,普遍的做法是手动将您的应用程序拆分为可以独立部署的独立微服务。 通过对各种基础设施团队的内部调查,我们发现大多数开发人员出于以下原因之一将他们的应用程序拆分为多个二进制包:(1) 提升性能。单独的二进制包可以独立扩展,从而提高资源利用率。 (2) 提升容错能力。一个微服务的崩溃不会导致其他微服务崩溃,从而限制了错误的传播范围。 (3) 改进抽象边界。微服务需要清晰明确的 API,并且代码纠缠的可能性会大大降低。 (4) 允许灵活的滚动发布。不同的二进制包可以以不同的速率发布,从而导致更敏捷的代码升级。 然而,将应用程序拆分为可独立部署的微服务并非没有挑战,其中一些直接与收益相矛盾。
- C1:影响性能。序列化数据并通过网络发送数据的开销越来越成为瓶颈 [72]。当开发人员过度拆分他们的应用程序时,这些开销也会增加 [55]。
- C2:损害正确性。推断每个微服务的每个已部署版本之间的交互是极具挑战性的。在对八个广泛使用的系统的 100 多个灾难性故障进行的案例研究中,三分之二的故障是由系统的多个版本之间的交互引起的 [78]。
- C3:很难管理。开发人员必须按照自己的发布计划管理不同的二进制包,而不是使用一个二进制文件来构建、测试和部署。如果在本地运行一个应用程序,同时需要执行端到端的集成测试,那可是一个不小的工程。
- C4:API 冻结。一旦微服务建立了 API,就很难在不破坏使用该 API 的其他服务的情况下进行更改。遗留的 API 不得不长期存在,只能不停的在上面打补丁。
- C5:降低应用程序的开发速度。当开发活动影响多个微服务的更改时,开发人员无法以原子方式实施和部署更改。
开发人员必须仔细计划规划发布时间表,已决定在何时跨微服务引入更改。根据我们的经验,我们发现许多开发人员将上述挑战视为开展业务的必要部分,并且这个比例是压倒性的。许多云原生公司实际上正在开发旨在缓解上述一些挑战的内部框架和流程,但这不会从根本上改变或完全消除它们。例如,
持续部署框架 [12, 22, 37] 简化了单个二进制包的构建、推送到生产环境的方式,但它们没有解决版本控制问题;如果它有提供这个能力的话,情况可能会更糟,因为代码将以更快的速度被发布并投入生产。各种编程库 [13、27] 使创建和发现网络端点变得更加容易,但对简化应用程序管理没有任何帮助。像 gRPC [18] 这样的网络协议和像 Protocol Buffers [30]这样的数据格式在不断改进,但仍然占据了应用程序执行成本的主要部分。
这些基于微服务的解决方案无法解决上述 C1-C5 的原因有两个。第一个原因是他们都假设开发人员手动将他们的应用程序拆分为多个二进制包。这意味着应用程序的网络布局由应用程序开发人员预先确定。此外,一旦确定,网络布局就会通过将网络代码添加到应用程序中而变得更加坚固(例如,网络端点、客户端/服务器存根、网络优化数据结构,如 [30] )。这意味着撤消或修改拆分变得更加困难,即使这样做是有意义的。这隐含地促成了上述挑战 C1、C2 和 C4。
第二个原因是假设应用程序二进制包是单独(在某些情况下是连续的)发布到生产环境中。这使得对跨二进制协议进行更改变得更加困难。此外,它还引入了版本控制问题并强制使用更低效的数据格式,如[23、30]。这反过来又会导致上面列出的挑战 C1-C5。
在本文中,我们提出了一种不同的编写和部署分布式应用程序的方法,一种解决 C1-C5 问题的方法。我们的编程方法包括三个核心原则:
- (1) 以模块化的方式编写逻辑上划分为多个组件的单体应用程序。
- (2) 利用运行时根据执行特征动态自动地将逻辑组件分配给物理进程。
- (3) 以原子方式部署应用程序,防止应用程序的不同版本交互。
其他解决方案(例如 actor 系统)也尝试提高抽象度。但是,它们无法解决其中一项或多项挑战(第 7 节)。尽管这些挑战和我们的提案是在服务型应用 (serving application) 的背景下讨论的,但我们相信我们的观察和解决方案具有广泛的用途。
2 提出的解决方案
我们提案的两个主要部分是 (1) 具有抽象的编程模型(programing model),允许开发人员编写仅关注业务逻辑的单一二进制模块化应用程序,(2) 用于构建、部署和优化这些应用程序的运行时(runtime)。
编程模型使开发人员能够将分布式应用程序编写为单个程序,其中代码被拆分为称为组件的模块化单元(第 3 节)。这类似于将应用程序拆分为微服务,除了微服务将逻辑和物理边界混为一谈。相反,我们的解决方案将两者分离:组件以基于应用程序业务逻辑的逻辑边界为中心,而运行时以基于应用程序性能的物理边界为中心(例如,两个组件应位于同一位置以提高性能)。这种解耦——连同边界可以自动更改的事实——解决了 C4。
通过将所有执行责任委托给运行时,我们的解决方案能够提供与微服务相同的优势,但性能更高,成本更低(解决 C1)。例如,运行时决定如何运行、放置、复制和缩放组件(第 4 节)。由于应用程序是原子部署的,因此运行时可以鸟瞰应用程序的执行情况,从而实现进一步的优化。例如,运行时可以使用自定义序列化和传输协议,利用所有参与者都以相同版本执行的事实。
将应用程序编写为单个二进制文件并以原子方式部署它还可以更轻松地推断其正确性(解决 C2)并使应用程序更易于管理(解决 C3)。我们的提案为开发人员提供了一个编程模型,使他们能够专注于应用程序业务逻辑,将部署复杂性委托给运行时(解决 C5)。最后,我们的提案支持未来的创新,例如分布式应用程序的自动化测试(第 5 节)。
3 编程模型
3.1 组件
我们提案的关键抽象是组件 (component)。组件是一种长期存在的、可复制的计算代理,类似于 actor [2]。每个组件都实现一个接口(interface),与组件交互的唯一方法是调用其接口上的方法。组件可能由不同的操作系统进程托管(可能跨越多台机器)。组件方法调用在必要时变成远程过程调用,但如果调用者和被调用者组件在同一个进程中,则仍然是本地过程调用。
组件如 图-1 所示。示例应用程序包含三个组件:A、B 和 C。当部署应用程序时,运行时决定如何共同定位和复制组件。在此示例中,组件 A 和组件 B 位于同一个操作系统进程中,因此它们之间的方法调用作为常规方法调用执行。组件 C 不与任何其他组件位于同一位置,同时组件 C 被部署到了两台不同机器上,组件 C 之间的方法调用是通过跨网络 RPC 完成的。
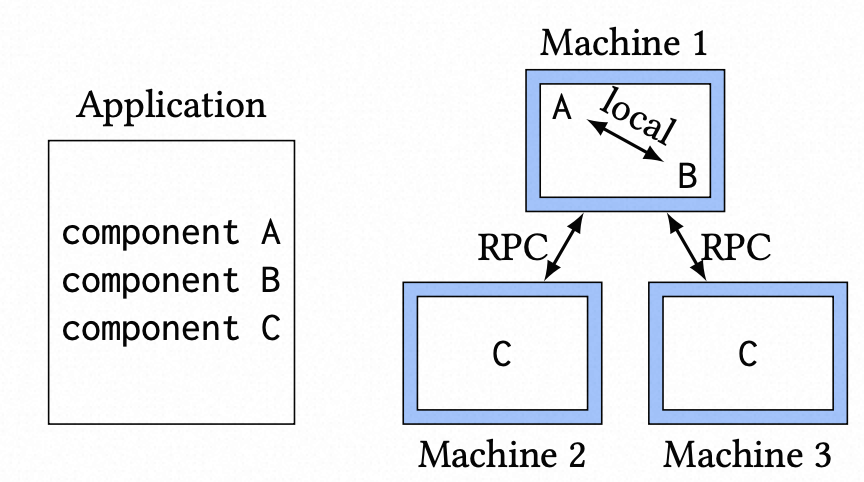
图-1:说明如何编写和部署组件。应用程序被编写为一组组件(左)并跨机器部署(右)。请注意,组件可以复制和放置在同一位置。
组件通常是长期存在的,但运行时可能会根据负载随时间增加或减少组件的副本数量。同样,组件副本可能会失败并重新启动。运行时还可以四处移动组件副本,例如,将两个交互非常多的组件放在同一个操作系统进程中,以便组件之间的通信在本地而不是通过网络完成。
3.2 接口
为了具体起见,我们在 Go 中提供了一个组件 API,尽管我们的想法与语言无关。图-2 给出了一个“Hello, World!” 应用程序。组件接口表示为 Go 接口,组件实现表示为实现这些接口的 Go 结构。在图-2 中, hello 结构嵌入了 **Implements[ Hello] **结构来表示它是 Hello 组件的实现。
**Init **初始化应用程序。**Get[Hello] **将客户端返回给具有接口 Hello 的组件,必要时创建它。对 hello.Greet 的调用看起来像是常规方法调用,开发人员不需要关心任何序列化和远程过程调用相关内容。

图-2: “Hello, World!” 应用
4 运行时
4.1 概述
在编程模型之下是一个负责分发(distributing)和执行(executing)组件的运行时。运行时做出关于如何运行组件的所有高级决策。例如,它决定将哪些组件放在一起并进行多副本部署。运行时还负责底层细节,例如将组件运行到物理资源以及在组件失败时重新启动组件。最后,运行时负责执行原子滚动更新,确保一个应用程序版本中的组件永远不会与不同版本中的组件进行通信。
有许多方法可以实现运行时。本文的目的不是规定任何特定的实现。不过,重要的是要认识到运行时并没有什么神奇魔法。在本节的其余部分,我们将概述运行时的关键部分并揭开其内部工作原理的神秘面纱。
4.2 代码生成
运行时的首要职责是代码生成。通过检查一个项目中使用 **Implements[T] **的相关源码调用,代码生成器即可计算出所有组件接口和实现的集合。然后它生成代码来编码和解码组件方法的参数。它还生成代码以将这些方法作为远程过程调用来执行。生成的代码将与开发人员的代码一起编译成一个二进制文件。
4.3 应用-运行时交互
根据我们的提案,应用程序不需要包含任何特定于其部署环境的代码,但由于它们最终必须运行并集成到特定环境中(例如在本地集群中跨机器或在公共云中跨区域运行),为了支持这种集成,我们引入了一个 API(在表-1 中进行了部分概述),它将应用程序逻辑与部署环境的细节隔离开来。

表-1:应用程序和运行时之间的示例 API。
API 的调用者是一个 proclet。每个应用程序二进制文件都会运行一个小型的、与环境无关的守护进程,称为 proclet,它在编译期间链接到二进制文件中。 proclet 管理正在运行的二进制文件中的组件:运行、启动、停止、在失败时重新启动这些组件等等。
API 的实现者是运行时,它负责所有控制平面操作。运行时决定 proclet 应该如何运行以及在何处运行。例如,多进程运行时可以运行子进程中的每个 proclet; SSH 运行时可以通过 SSH 运行 proclet;云运行时可以将 proclet 作为 Kubernetes pod [25、28] 运行。
具体而言,proclet 通过 Unix Pipeline 与运行时交互。例如,当构造一个 proclet 时,它会通过管道发送一条 RegisterReplica 消息,以将自己标记为活动和就绪。它定期发出 ComponentsToHost 请求以了解它应该运行哪些组件。如果组件调用不同组件的方法,proclet 会发出 StartComponent 请求以确保它已启动。
运行时以对部署环境有意义的方式实现这些 API。我们希望大多数运行时实现包含以下两部分:
- (1) 一组通过 UNIX 管道与 proclet 直接通信的信封(Envelope)进程,以及
- (2) 协调 proclet 执行的全局管理器(Global Manager)(参见图-3)。
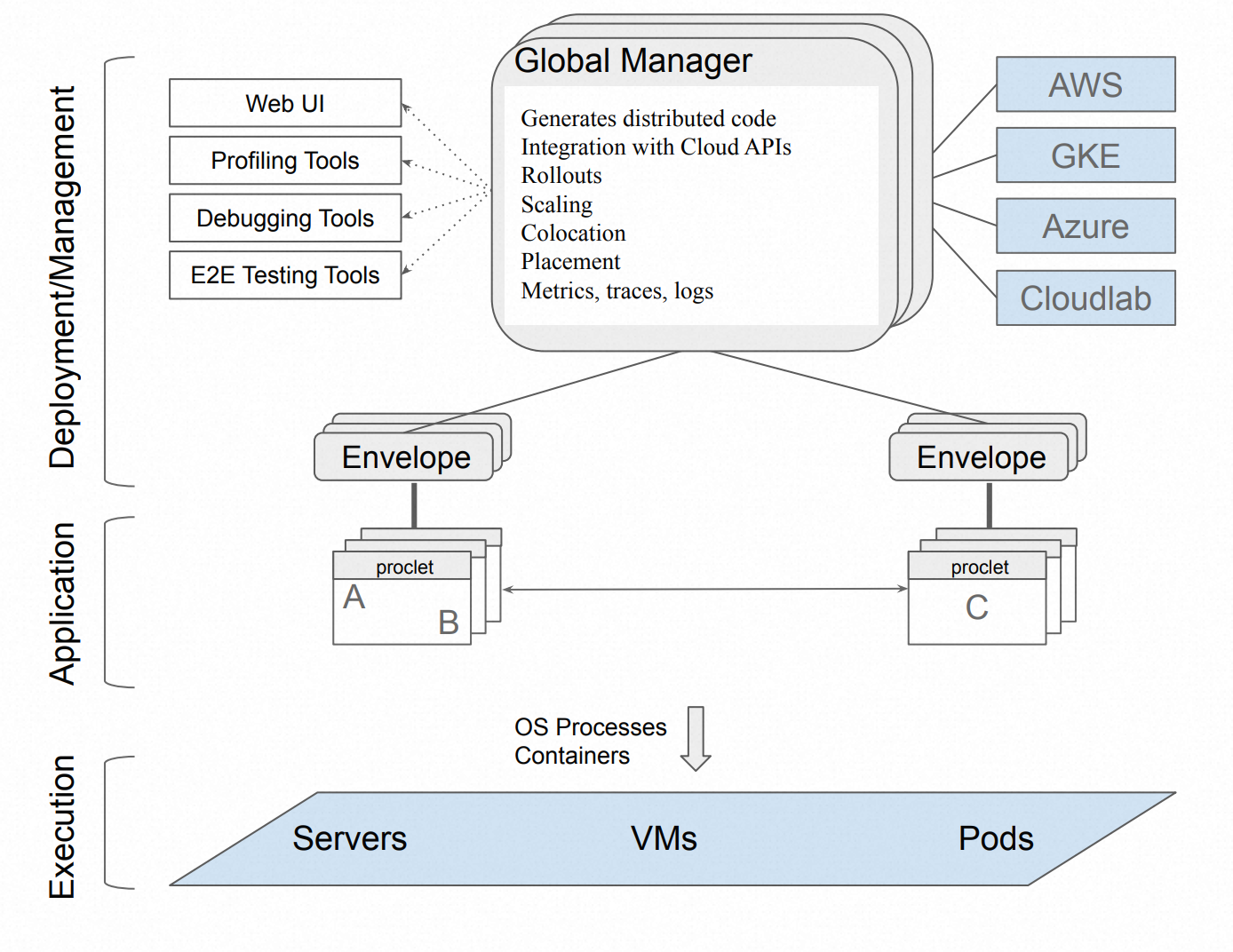
图-3:提案中的 Deployer 架构
信封(Envelope)作为 proclet 的父进程运行,并将 API 调用中继到管理器。管理器跨可用资源集(例如服务器、VM)启动信封和(间接)proclet。在应用程序的整个生命周期中,管理器与信封交互以收集运行组件的健康和负载信息;聚合组件导出的指标、日志和跟踪;并处理启动新组件的请求。管理器还发布特定于环境的 API(例如,谷歌云[16]、AWS [4])更新流量分配并根据负载、健康状况和性能约束扩展和缩减组件。请注意,运行时实现控制平面(Golbal Manager)而不是数据平面,Proclet 直接相互通信。
4.4 原子滚动更新(Rollout)
开发人员不可避免地必须发布其应用程序的新版本。一种广泛使用的方法是执行滚动更新,其中部署中的机器一台一台地从旧版本更新到新版本。在滚动更新期间,运行不同版本代码的机器必须相互通信,这可能会导致失败。 [78]表明大多数更新失败是由这些跨版本交互引起的。 为了解决这些复杂性,我们提出了一种不同的方法。运行时确保应用程序版本以原子方式推出,这意味着所有组件通信都发生在应用程序的单个版本中。运行时逐渐将流量从旧版本转移到新版本,但是一旦用户请求转发到特定版本,它就会完全在该版本内处理。原子部署的一种流行实现是使用蓝/绿部署[9]。
5 启用创新
5.1 传输(Transport)、放置(Placement)和缩容(Scaling)
运行时可以鸟瞰应用程序执行,这为性能优化开辟了新途径。例如,我们的框架可以在组件之间构建一个细粒度的调用图,并用它来识别关键的路径路径、瓶颈组件、频繁交互型组件等。使用这些信息,运行时可以做出更智能的扩缩容、独立部署和组合部署决策。此外,由于序列化和传输机制对开发者透明(Code Generate 机制自动实现),运行时可以自由地优化它们。例如,对于网络瓶颈应用程序,运行时可能决定压缩网络上的消息,对于某些部署,传输可能会利用 RDMA [32] 等技术。
5.2 路由(Routing)
当请求以亲和力(affinity)路由时,某些组件的性能会大大提高。例如,考虑由基于磁盘的底层存储系统支持的内存缓存组件。当对相同键的请求被路由到相同的缓存副本时,缓存命中率和整体性能会提高。 Slicer [44]表明,许多应用程序可以从这种基于亲和力的路由中受益,并且当路由嵌入到应用程序本身时,路由效率最高[43]。我们的编程框架可以自然地扩展为包含路由 API。运行时还可以了解哪些方法从路由中获益最多并自动路由它们。
5.3 自动化测试(Automated Testing)
微服务架构被吹捧的好处之一是容错。这个想法是,如果应用中的一个服务组件失败,应用的部分功能可用性会降低,但整个应用仍然可用。这在理论上很棒,但在实践中它依赖于开发人员确保他们的应用对故障具有弹性,更重要的是,测试他们的故障处理逻辑是否正确。由于构建和运行不同的微服务、系统地失败和恢复它们以及检查正确行为的开销,测试尤其具有挑战性。结果,只有一小部分基于微服务的系统针对这种类型的容错进行了测试。根据我们的建议,运行端到端测试能带来的帮助是微不足道的。因为应用程序是用单一编程语言编写的单个二进制文件,所以端到端测试变成了简单的单元测试。这为自动化容错测试打开了大门,类似于混沌测试[47]、Jepsen 测试[14]和模型检查[62]。
5.4 有状态应用滚动更新(Rollout)
我们的建议确保一个应用程序版本中的组件永远不会与不同版本中的组件通信。这使开发人员更容易推理正确性。但是,如果应用程序更新持久存储系统(如数据库)中的状态,则应用程序的不同版本将通过它们读取和写入的数据间接影响彼此。这些跨版本交互是不可避免的——持久状态,根据定义,跨版本持续存在 —— 但一个悬而未决的问题是如何测试这些交互并及早发现错误以避免在推出期间出现灾难性故障。
5.5 讨论
请注意,本节讨论的领域中的创新并不是我们提案所独有的。对传输协议[63、64]、路由[44、65]、测试[45、75]、资源管理[57、67、71]、故障排除[54、56]等。然而,我们的编程模型的独特功能支持新的创新,并使现有的创新更容易实现实施。
例如,通过在我们的提议中利用原子部署,我们可以设计高效的序列化协议,可以安全地假设所有参与者都使用相同的模式。此外,我们的编程模型可以轻松地将路由逻辑直接嵌入到用户的应用程序中,从而提供一系列好处[43]。同样,我们的提案提供应用程序鸟瞰图的能力允许 研究人员专注于开发用于调整应用程序和降低部署成本的新解决方案。
6 原型实现
我们的原型实现是用 Go [38]编写的,包括图2 中描述的组件 API、第4.2节中描述的代码生成器以及第 4.3 节中描述的 proclet 架构。该实现使用自定义序列化格式和直接构建在 TCP 之上的自定义传输协议。该原型还带有一个谷歌 Kubernetes 引擎 (GKE) 部署器,它通过渐进的蓝/绿部署实现多区域部署。它使用 Horizontal Pod Autoscalers [20]根据负载动态调整容器副本的数量,并遵循类似于图3中的架构。我们的实现可在github.com/ServiceWeaver 获得。
6.1 评价
为了评估我们的原型,我们使用了一个流行的 Web 应用程序[41],它代表了开发人员编写的各种微服务应用程序。该应用程序有 11 个微服务,并使用 gRPC [18]和 Kubernetes [25]部署在云端。该应用程序是用各种编程语言编写的,因此为了公平比较,我们将应用程序移植为完全用 Go 编写。然后我们将应用程序移植到我们的原型中,每个微服务都被重写为一个组件。我们使用 Locust [26],一种工作负载生成器,在有和没有我们的原型的情况下对应用程序进行负载测试。
工作负载生成器向应用程序发送稳定速率的 HTTP 请求。两个应用程序版本都配置为自动缩放容器副本的数量以响应负载。我们测量了应用程序版本在稳定状态下使用的 CPU 内核数量,以及它们的端到端延迟。表-2 显示了我们的结果。

表-2
我们原型的大部分性能优势来自它使用专为非版本化数据交换设计的自定义序列化格式,以及它使用直接构建在 TCP 之上的流线型传输协议。例如,使用的序列化格式不需要对字段编号或类型信息进行任何编码。这是因为所有编码器和解码器都以完全相同的版本运行,并且预先就字段集以及它们的编码和解码顺序达成一致。
为了与基线进行同类比较,我们没有将任何组件放在一起。当我们共同定位所有将 11 个组件集成到单个操作系统进程中,内核数量下降到 9,中值延迟下降到 0.38 毫秒,均比基线低一个数量级。这反映了行业经验[34、39]。
7 相关工作
演员系统。最接近我们建议的解决方案是 Orleans [74]和 Akka [3]。这些框架还使用抽象来解耦应用程序和运行时。 Ray [70]是另一个基于角色的框架,但专注于 ML 应用程序。这些系统都不支持原子部署,而原子部署是完全应对 C2-C5 挑战的必要组成部分。其他流行的基于 actor 的框架,如 Er-lang [61]、E [52]、Thorn [48]和 C++ Actor Framework [10],给开发人员带来了处理系统和有关部署和执行的低级细节的负担,因此它们未能分离应用程序和运行时之间的关注点,因此没有完全解决 C1-C5。 CORBA、DCOM 和 Java RMI 等分布式对象框架使用与我们类似的编程模型,但存在许多技术和组织问题[58],并且也没有完全解决 C1-C5。
基于微服务的系统。 Kubernetes [25]广泛用于在云中部署基于容器的应用程序。但是,它的重点与我们的提案正交,不涉及 C1-C5 中的任何一个。 Docker Compose [15]、Acorn [1]、Helm [19]、Skaffold [35]和 Istio [21]抽象出了一些微服务挑战(例如,配置生成)。然而,与将应用程序拆分为微服务、版本化推出和测试相关的挑战仍然留给了用户。因此,它们不满足 C1-C5。
其他系统。还有许多其他解决方案可以让开发人员更轻松地编写分布式应用程序,包括数据流系统[51、59、77]、ML 推理服务系统[8、17、42、50、73]、无服务器解决方案[11, 24、36]、数据库[29、49]和 Web 应用程序[66]。最近,服务网格[46、69]提出了网络抽象以分解出常见的通信功能。我们的提案体现了这些相同的想法,但在通用服务系统和分布式应用程序的新领域中。在这种情况下,出现了新的挑战(例如,原子推出)。
8 讨论
8.1 多个应用程序二进制文件
我们认为应用程序应该作为单个二进制文件来编写和构建,但我们承认这可能并不总是可行的。例如,应用程序的大小可能超出单个团队的能力,或者不同的应用程序服务可能出于组织原因需要不同的发布周期。在所有这些情况下,应用程序可能需要包含多个二进制文件。
虽然本文没有解决需要使用多个二进制文件的情况,但我们相信我们的提议允许开发人员编写更少的二进制文件(即尽可能将多个服务分组为单个二进制文件),实现更好的性能,并推迟做出艰难的决定与如何划分应用程序有关。我们正在探索如何容纳以多种语言编写并编译成单独的二进制文件的应用程序。
8.2 与外部服务集成
应用程序通常需要与外部服务(例如,Postgres 数据库[29])进行交互。我们的编程模型允许应用程序像任何应用程序一样与这些服务交互。什么都不是,一切都必须是一个组件。但是,当外部服务在应用程序内部和跨应用程序广泛使用时,定义相应的组件可能会提供更好的代码重用。
8.3 分布式系统挑战
虽然我们的编程模型允许开发人员专注于他们的业务逻辑并推迟将他们的应用程序部署到运行时的大量复杂性,但我们的提议并没有解决分布式系统的基本挑战 [53, 68, 76]。应用程序开发人员仍然需要意识到组件可能会失败或经历高延迟。
8.4 编程指导
没有关于如何编写分布式应用程序的官方指南,因此关于将应用程序编写为单体应用程序还是微服务是更好的选择,一直存在着长期而激烈的争论。但是,每种方法都有其优点和缺点。我们认为开发人员应该使用我们的建议将他们的应用程序编写为单个二进制文件,然后再决定他们是否真的需要迁移到基于微服务的架构。通过推迟决定如何准确地拆分成不同的微服务,它允许他们编写更少但更好的微服务。
9 结论
编写分布式应用程序时的现状涉及将应用程序拆分为可独立部署的服务。这种架构有很多好处,但也有很多缺点。在本文中,我们提出了一种不同的编程范式来回避这些缺点。我们的提议鼓励开发人员 (1) 编写划分为逻辑组件的单体应用程序,(2) 将物理分布和执行模块化单体的挑战推迟到运行时,以及 (3) 原子部署应用程序。这三个指导原则带来了许多好处,并为未来的创新打开了大门。与现状相比,我们的原型实施将应用程序延迟最多减少了 15 倍,并将成本最多减少了 9 倍。
[1] Acorn. https://www.acorn.io/.
[2] Actor model. https://en.wikipedia.org/wiki/Actor_model.
[3] Akka. https://akka.io.
[4] Amazon Web Services. https://aws.amazon.com/.
[5] Apache avro. https://avro.apache.org/docs/1.2.0/.
[6] Apache thrift. https://thrift.apache.org/.
[7] AWS Cloud Map. https://aws.amazon.com/cloud-map/.
[8] Azure Machine Learning. https://docs.microsoft.com/en-us/azure/machine-learning.
[9] Blue/green deployments. https://tinyurl.com/3bk64ch2.
[10] The c++ actor framework. https://www.actor-framework.org/.
[11] Cloudflare Workers. https://workers.cloudflare.com/.
[12] Continuous integration and delivery - circleci. https://circleci.com/.
[13] Dapr - distributed application runtime. https://dapr.io/.
[14] Distributed systems safety research. https://jespen.io.
[15] Docker compose. https://docs.docker.com/compose/.
[16] Google Cloud. https://cloud.google.com/.
[17] Google Cloud AI Platform. https://cloud.google.com/ai-platform.
[18] grpc. https://grpc.io/.
[19] Helm. http://helm.sh.
[20] Horizontal Pod Autoscaling. https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/.
[21] Istio. https://istio.io/.
[22] Jenkins. https://www.jenkins.io/.
[23] Json. https://www.json.org/json-en.html.
[24] Kalix. https://www.kalix.io/.
[25] Kubernetes. https://kubernetes.io/.
[26] Locust. https://locust.io/.
[27] Micro | powering the future of cloud. https://micro.dev/.
[28] Pods. https://kubernetes.io/docs/concepts/workloads/pods/.
[29] Postgresql. https://www.postgresql.org/.
[30] Protocol buffers. https://developers.google.com/protocol-buffers.
[31] RabbitMQ. https://www.rabbitmq.com/.
[32] Remote direct memory access. https://en.wikipedia.org/wiki/Remote_direct_memory_access.
[33] REST API. https://restfulapi.net/.
[34] Scaling up the Prime Video audio/video monitoring service and reduc-ing costs by 90%. https://tinyurl.com/yt6nxt63.
[35] Skaffold. https://skaffold.dev/.
[36] Temporal. https://temporal.io/.
[37] Terraform. https://www.terraform.io/.
[38] The Go programming language. https://go.dev/.
[39] To Microservices and Back Again - Why Segment Went Back to a Monolith. https://tinyurl.com/5932ce5n.
[40] WebSocket. https://en.wikipedia.org/wiki/WebSocket.
[41] Online boutique. https://github.com/GoogleCloudPlatform/microservices-demo,2023.
[42] M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis, J. Dean, M. Devin, S.Ghemawat, G. Irving, M. Isard, M. Kudlur, J. Levenberg, R. Monga, S.Moore, D. G. Murray, B. Steiner, P. Tucker, V. Vasudevan, P. Warden, M.Wicke, Y. Yu, and X. Zheng. Tensorflow: A system for large-scale machine learning. In OSDI, 2016.
[43] A. Adya, R. Grandl, D. Myers, and H. Qin. Fast key-value stores: An idea whose time has come and gone. In HotOS, 2019.
[44] A. Adya, D. Myers, J. Howell, J. Elson, C. Meek, V. Khemani, S. Fulger, P.Gu, L. Bhuvanagiri, J. Hunter, R. Peon, L. Kai, A. Shraer, A. Merchant, and K. Lev-Ari. Slicer: Auto-sharding for datacenter applications. In OSDI, 2016.
[45] D. Ardelean, A. Diwan, and C. Erdman. Performance analysis of cloud applications. In NSDI, 2018.
[46] S. Ashok, P. B. Godfrey, and R. Mittal. Leveraging service meshes as a new network layer. In HotNets, 2021.
[47] A. Basiri, N. Behnam, R. De Rooij, L. Hochstein, L. Kosewski, J.Reynolds, and C. Rosenthal. Chaos engineering. In IEEE Software, 2016.
[48] B. Bloom, J. Field, N. Nystrom, J. Östlund, G. Richards, R. Strniša, J.Vitek, and T. Wrigstad. Thorn: Robust, concurrent, extensible script-ing on the jvm. In OOPSLA, 2009.
[49] J. C. Corbett, J. Dean, M. Epstein, A. Fikes, C. Frost, J. J. Furman, S. Ghe-mawat, A. Gubarev, C. Heiser, P. Hochschild, W. Hsieh, S. Kanthak, E.Kogan, H. Li, A. Lloyd, S. Melnik, D. Mwaura, D. Nagle, S. Quin-lan, R. Rao, L. Rolig, Y. Saito, M. Szymaniak, C. Taylor, R. Wang, and D.Woodford. Spanner: Google’s globally-distributed database. In OSDI, 2012.
[50] D. Crankshaw, X. Wang, G. Zhou, M. J. Franklin, J. E. Gonzalez, and I.Stoica. Clipper: A low-latency online prediction serving system. In NSDI, 2017.
[51] J. Dean and S. Ghemawat. Mapreduce: Simplified data processing on large clusters. In OSDI, 2004. [52] J. Eker, J. Janneck, E. Lee, J. Liu, X. Liu, J. Ludvig, S. Neuendorffer, S.Sachs, and Y. Xiong. Taming heterogeneity - the ptolemy approach. In Proceedings of the IEEE, 2003.
[53] M. J. Fischer, N. A. Lynch, and M. S. Paterson. Impossibility of dis-tributed consensus with one faulty process. In ACM Journal, 1985.
[54] Y. Gan, M. Liang, S. Dev, D. Lo, and C. Delimitrou. Sage: Practical and Scalable ML-Driven Performance Debugging in Microservices. In ASPLOS, 2021.
[55] Y. Gan, Y. Zhang, D. Cheng, A. Shetty, P. Rathi, N. Katarki, A. Bruno, J.Hu, B. Ritchken, B. Jackson, et al. An open-source benchmark suite for microservices and their hardware-software implications for cloud & edge systems. In ASPLOS, 2019.
[56] Y. Gan, Y. Zhang, K. Hu, Y. He, M. Pancholi, D. Cheng, and C. De-limitrou. Seer: Leveraging Big Data to Navigate the Complexity of Performance Debugging in Cloud Microservices. In ASPLOS, 2019.
[57] R. Grandl, G. Ananthanarayanan, S. Kandula, S. Rao, and A. Akella. Multi-resource packing for cluster schedulers. In SIGCOMM, 2014.
[58] M. Henning. The rise and fall of corba: There’s a lot we can learn from corba’s mistakes. In Queue, 2006.
[59] M. Isard, M. Budiu, Y. Yu, A. Birrell, and D. Fetterly. Dryad: Distributed data-parallel programs from sequential building blocks. In Eurosys, 2007.
[60] K. Jay, N. Neha, and R. Jun. Kafka : a distributed messaging system for log processing. In NetDB, 2011.
[61] A. Joe. Erlang. In Communications of the ACM, 2010.
[62] L. Lamport. The temporal logic of actions. In ACM TOPLS, 1994.
[63] A. Langley, A. Riddoch, A. Wilk, A. Vicente, C. Krasic, D. Zhang, F.Yang, F. Kouranov, I. Swett, J. Iyengar, J. Bailey, J. Dorfman, J. Roskind, J.Kulik, P. Westin, R. Tenneti, R. Shade, R. Hamilton, V. Vasiliev, W.-T. Chang, and Z. Shi. The quic transport protocol: Design and internet-scale deployment. In SIGCOMM, 2017.
[64] N. Lazarev, N. Adit, S. Xiang, Z. Zhang, and C. Delimitrou. Dagger: Towards Efficient RPCs in Cloud Microservices with Near-Memory Reconfigurable NICs. In ASPLOS, 2021.
[65] S. Lee, Z. Guo, O. Sunercan, J. Ying, T. Kooburat, S. Biswal, J. Chen, K.Huang, Y. Cheung, Y. Zhou, K. Veeraraghavan, B. Damani, P. M. Ruiz, V.Mehta, and C. Tang. Shard manager: A generic shard management framework for geo-distributed applications. In SOSP, 2021.
[66] B. Livshits and E. Kiciman. Doloto: Code splitting for network-bound web 2.0 applications. In FSE, 2008.
[67] S. Luo, H. Xu, C. Lu, K. Ye, G. Xu, L. Zhang, Y. Ding, J. He, and C. Xu. Characterizing microservice dependency and performance: Alibaba trace analysis. In SOCC, 2021.
[68] N. A. Lynch. Distributed algorithms. In Morgan Kaufmann Publishers Inc., 1996.
[69] S. McClure, S. Ratnasamy, D. Bansal, and J. Padhye. Rethinking net-working abstractions for cloud tenants. In HotOS, 2021.
[70] P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, M. Eli-bol, Z. Yang, W. Paul, M. I. Jordan, and I. Stoica. Ray: A distributed framework for emerging ai applications. In OSDI, 2018.
[71] H. Qiu, S. S. Banerjee, S. Jha, Z. T. Kalbarczyk, and R. K. Iyer. FIRM: An intelligent fine-grained resource management framework for SLO-Oriented microservices. In OSDI, 2020.
[72] D. Raghavan, P. Levis, M. Zaharia, and I. Zhang. Breakfast of champi-ons: towards zero-copy serialization with nic scatter-gather. In HotOS, 2021.
[73] F. Romero, Q. Li, N. J. Yadwadkar, and C. Kozyrakis. Infaas: Automated model-less inference serving. In ATC, 2021.
[74] B. Sergey, G. Allan, K. Gabriel, L. James, P. Ravi, and T. Jorgen. Orleans: Cloud computing for everyong. In SOCC, 2011.
[75] M. Waseem, P. Liang, G. Márquez, and A. D. Salle. Testing microser-vices architecture-based applications: A systematic mapping study. In APSEC, 2020.
[76] Wikipedia contributors. Fallacies of distributed computing.
[77] M. Zaharia, M. Chowdhury, T. Das, A. Dave, J. Ma, M. McCauly, M. J. Franklin, S. Shenker, and I. Stoica. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In NSDI, 2012.
[78] Y. Zhang, J. Yang, Z. Jin, U. Sethi, K. Rodrigues, S. Lu, and D. Yuan. Understanding and detecting software upgrade failures in distributed systems. In SOSP, 2021.