该文章内容发布已经超过一年,请注意检查文章中内容是否过时。
工商银行 Dubbo3 应用级服务发现实践
问题分析
以下是经典的 Dubbo 的工作原理图,服务提供者和消费者通过注册中心协调实现地址的自动发现。
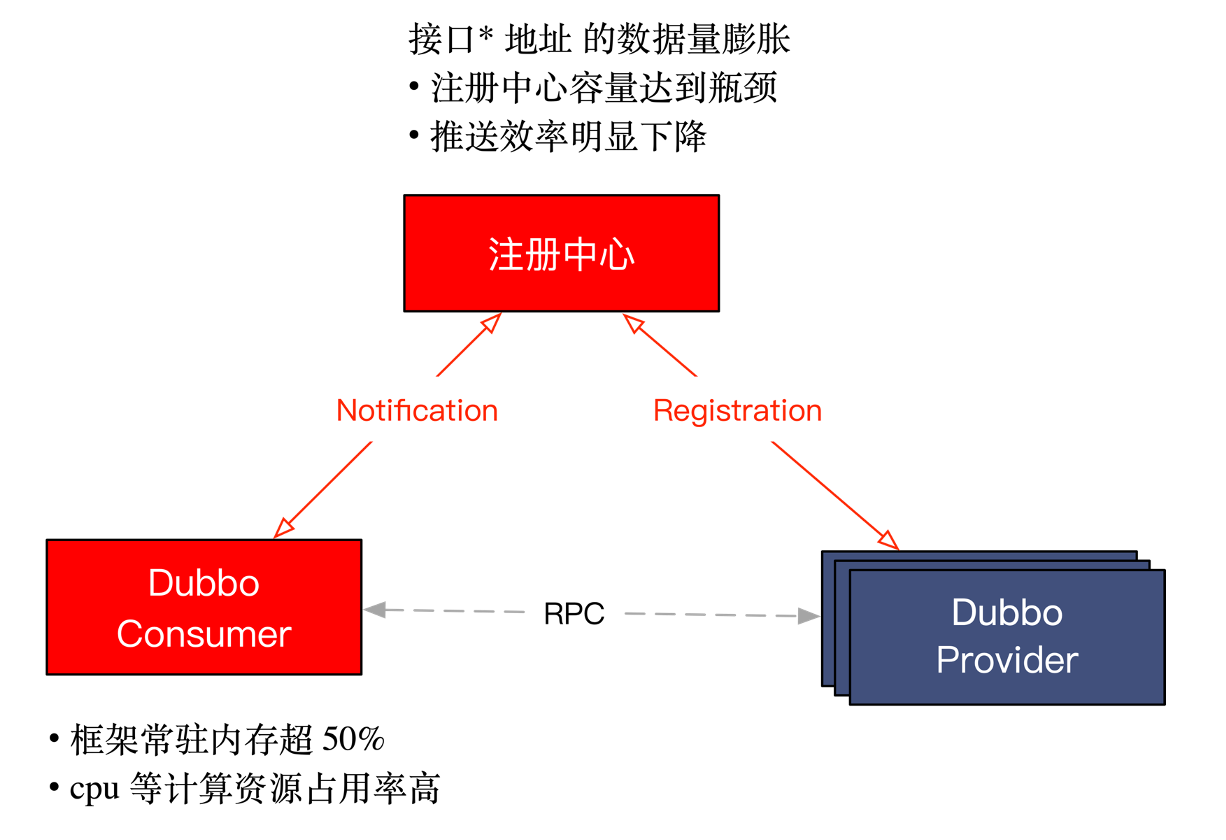
工商银行面临的主要瓶颈是在注册中心与服务消费端,接口级别地址的数量已经是亿级规模,一方面存储容量达到瓶颈、另一方面推送效率明显下降;而在消费端这一侧,Dubbo2 框架常驻内存已超 40%,每次地址推送带来的 cpu 等资源消耗率也非常高,影响正常的业务调用。
这是 Dubbo2 接口级服务发现架构在大规模集群场景下的固有问题(具体原因请查看应用级服务发现原理解析),通过常规的性能优化无法从根本上解决问题。因此工商银行采用了 Dubbo3 中提出的应用级服务发现模型,经过实测,新的服务发现模型能实现节点到注册中心间数据传输量 90% 的下降,这就使得注册中心的压力极大降低,同时消费端的框架常驻内存也实现超 50% 下降。
压测数据
下面是工商银行联合 Dubbo 社区给出的一组基于真实服务特点给出的模拟压测数据。
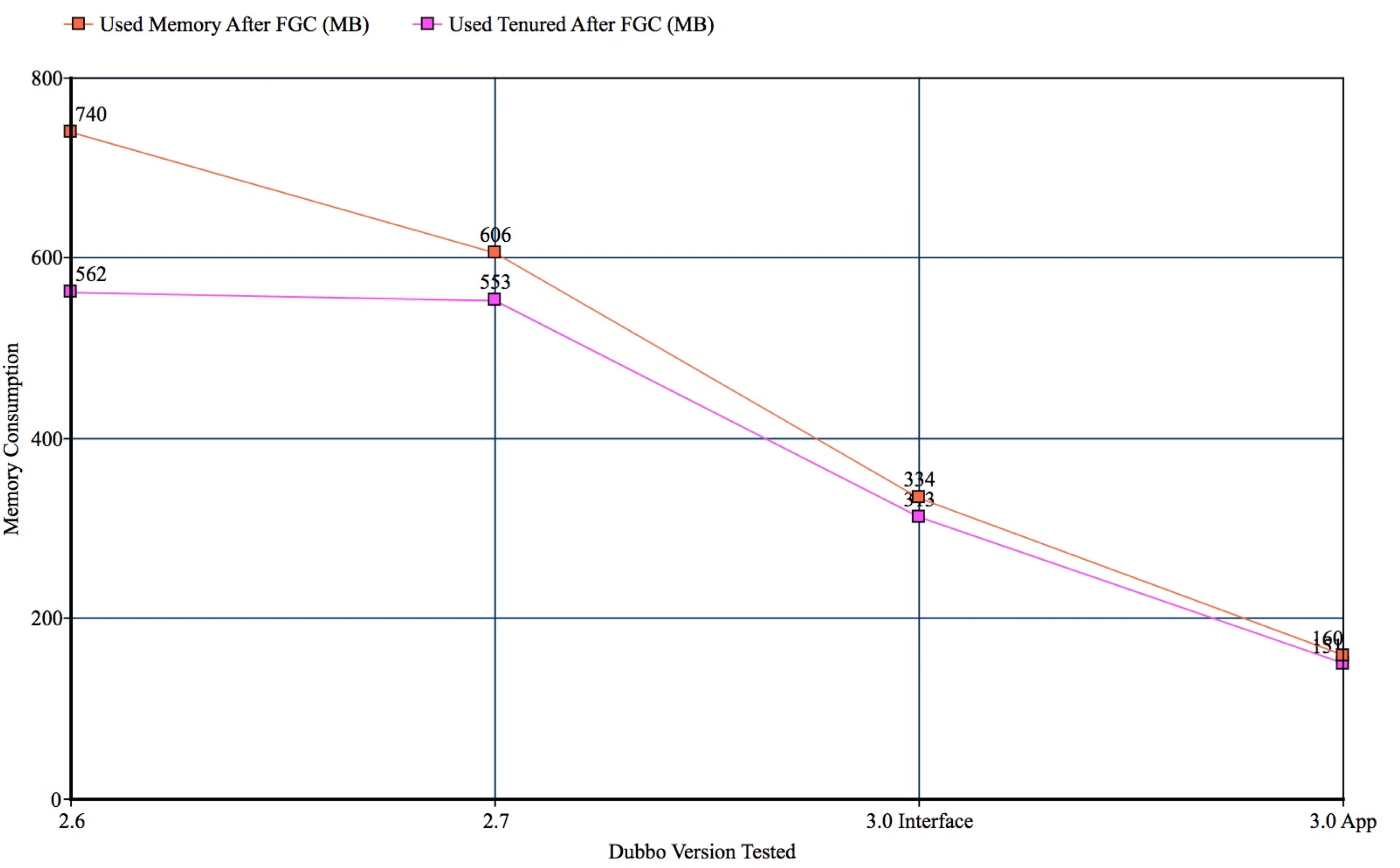
上图是对使用了应用级服务发现的消费端进程采样的内存对比数据。其中横轴是不同的 Dubbo 版本,纵轴是实际采样到的内存表现,可以看到 Dubbo 2.6、2.7 版本表现几乎一致,而升级到 3.0 版本后,即使不升级应用级服务发现,内存也降低接近 40%,而当切换到应用级服务发现之后,内存占用下降到只有原来的 30%。
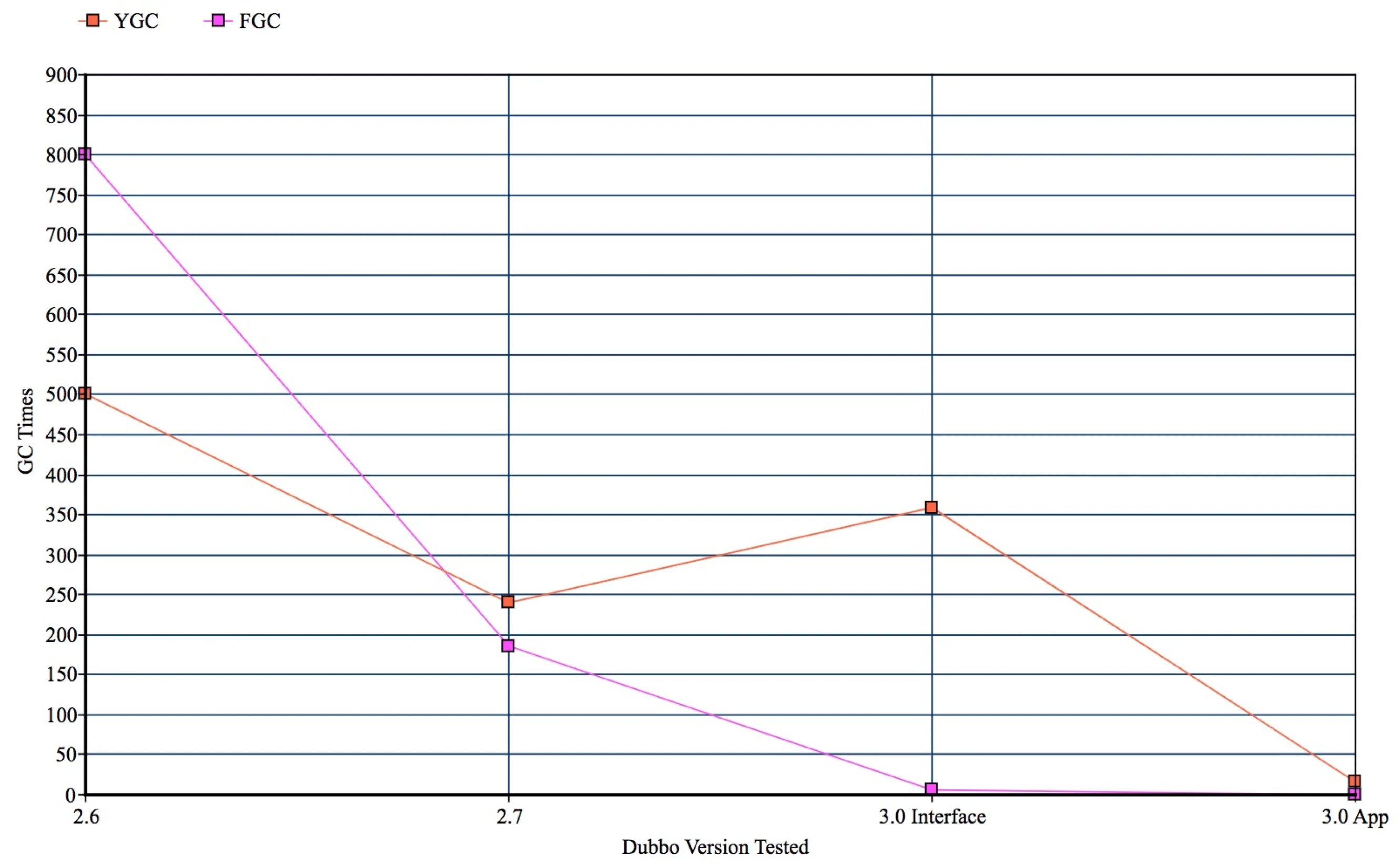
上图是消费端的 GC 情况统计,同样的,横轴是不同的 Dubbo 版本,纵轴是实际采样到的 GC 表现。这里的压测数据,是通过模拟注册中心不停的往消费端进程推送地址列表的场景得到的。可以看到 Dubbo 2.6、2.7 版本表现几乎一致,而在 3.0 版本中切换到应用级服务发现之后,GC 已经趋近于零次。