This article is more than one year old. Older articles may contain outdated content. Check that the information in the page has not become incorrect since its publication.
Dubbo3 Application-Level Service Discovery Design
Objective
- Significantly reduce resource consumption during the service discovery process, including increasing the registration center’s capacity limit and reducing resource usage for consumer address resolution, allowing the Dubbo3 framework to support larger-scale cluster service governance and achieve unlimited horizontal scalability.
- Adapt to underlying infrastructure service discovery models such as Kubernetes, Service Mesh, etc.
Background
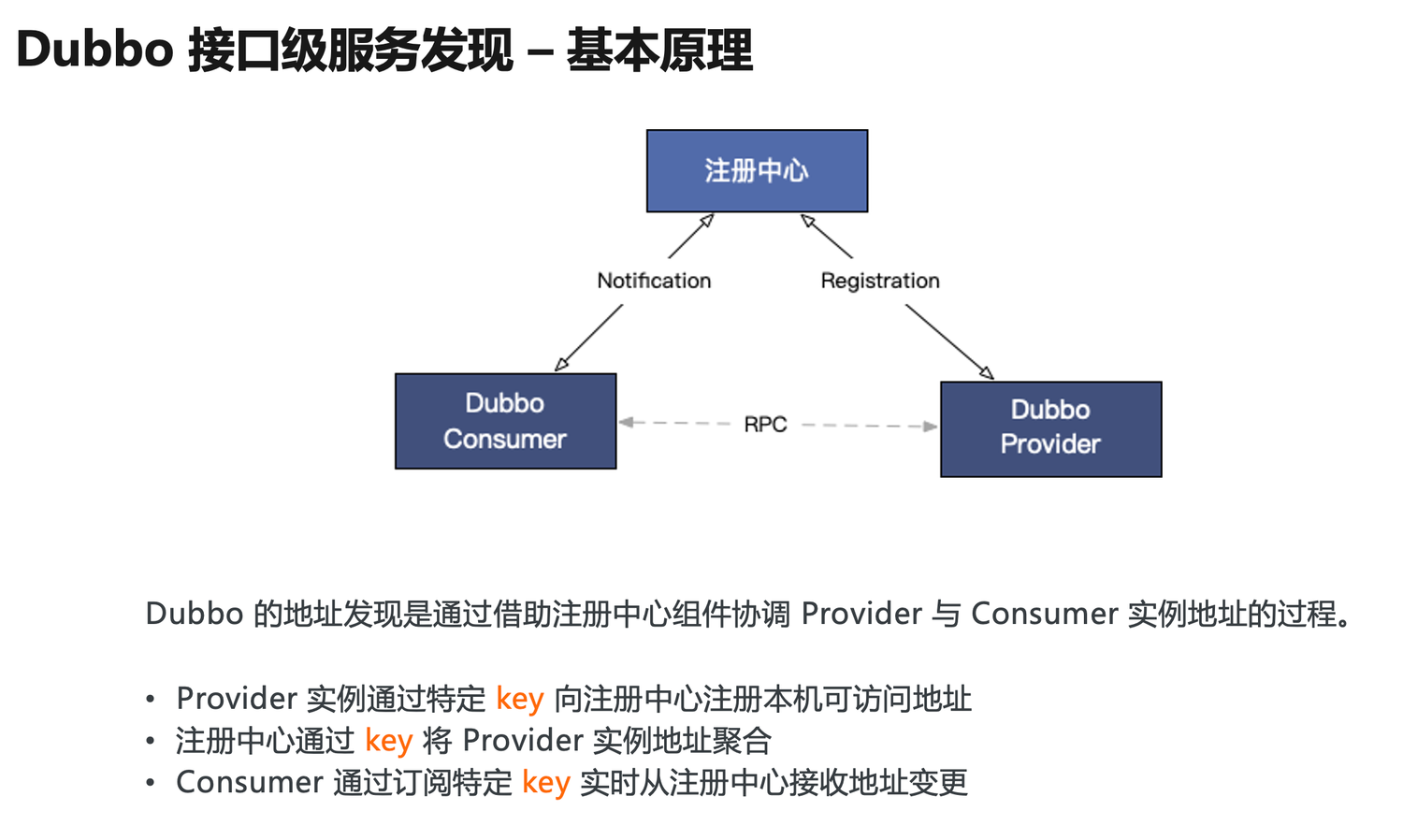
We start with the classic working principle diagram of Dubbo; from its design inception, Dubbo has built-in capabilities for service address discovery. Providers register their addresses with the registration center, and consumers subscribe to receive real-time updates about address changes from the registration center. Upon receiving the address list, consumers initiate RPC calls to providers based on specific load balancing strategies.
In this process:
- Each provider registers its accessible address with the registration center using a specific key;
- The registration center aggregates provider instance addresses using this key;
- Consumers subscribe from the registration center using the same key to receive the aggregated address list in a timely manner;
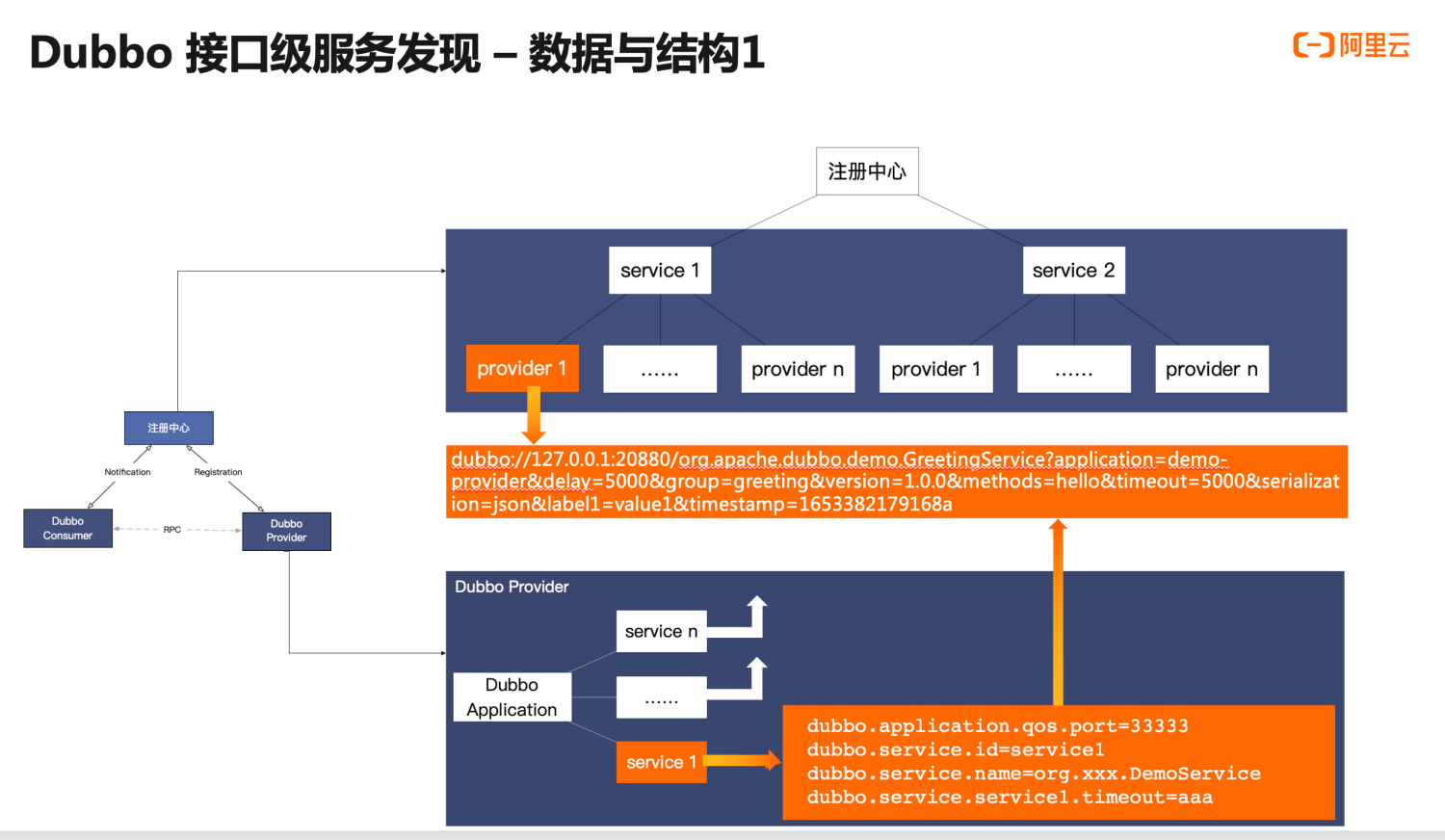
Here, we perform a detailed analysis of the internal data structure of interface-level address discovery.
First, let’s look at the internal data and behaviors of the provider instances in the lower right corner. Applications deployed by providers typically have multiple services, corresponding to services in Dubbo2, each potentially having unique configurations. The service deployment process we discuss here is actually the process of generating address URLs based on service configurations, as shown in the generated address data; similarly, other services will also generate addresses.
Then, consider the address data storage structure of the registration center. The registration center uses service names as the basis for data segmentation, aggregating all address data for a service as child nodes, where the content of child nodes is the actual accessible IP addresses, which corresponds to our Dubbo URLs, formatted as generated by the provider instances.

Here the URL address data is divided into several parts:
- Firstly, the accessible instance addresses, with key information including IP and port, are used by consumers to generate TCP network connections for transmitting subsequent RPC data.
- Secondly, there is RPC metadata, which defines and describes an RPC request. It indicates that this address data relates to a specific RPC service, with its version number, group, and method-related information.
- The next part consists of RPC configuration data, which includes configurations to control RPC call behavior, as well as some to synchronize the state of the provider process instances, typically such as timeout and serialization method.
- The final part is custom metadata, which differs from the predefined configurations above, allowing users more flexibility to extend and add custom metadata to enrich instance state.
Combining the analysis of Dubbo2’s interface-level address model from the previous two pages, along with the basic principle diagram of Dubbo at the outset, we can draw a few conclusions:
- First, the key for address discovery aggregation is the RPC granular service.
- Second, the data synchronized by the registration center includes not only addresses but also various metadata and configurations.
- Thanks to 1 and 2, Dubbo achieves service governance capabilities at the application, RPC service, and method level.
This is the true reason why Dubbo2 has always excelled over many service frameworks in usability, service governance functionality, and scalability.
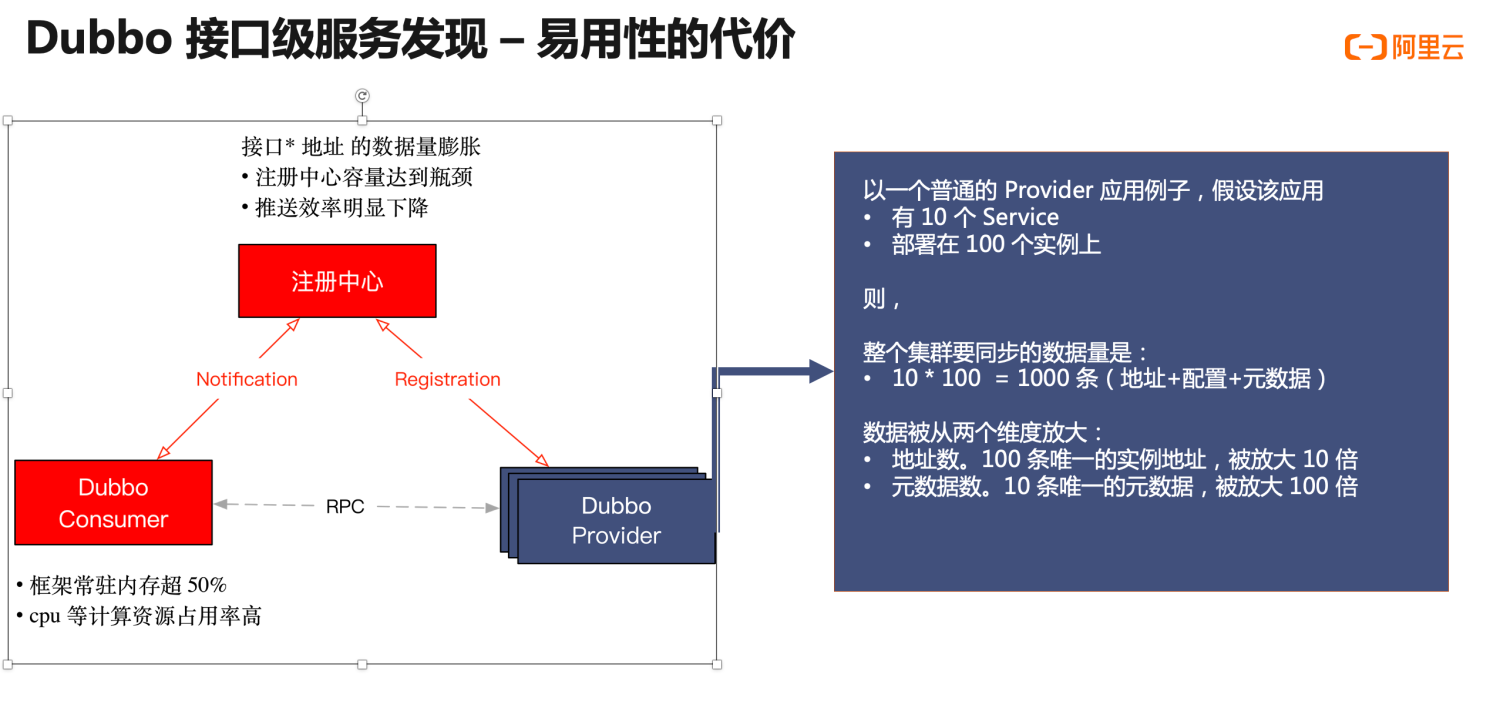
Every entity has two sides, and while the Dubbo2 address model brings ease of use and powerful features, it also imposes some limitations on the horizontal scalability of the entire architecture. This issue is typically imperceptible in average-scale microservice clusters. However, as the cluster scales, when the number of applications and machines within the entire cluster reaches a certain level, the components across the cluster begin to encounter scale bottlenecks. After summarizing the production environment characteristics of several typical users, including Alibaba and ICBC, we identified the following two prominent issues (as indicated in red in the image):
- First, the registration center cluster reaches its maximum capacity threshold. Since all URL address data is sent to the registration center, the storage capacity of the registration center hits its limit, which reduces push efficiency.
- On the consumer side, the Dubbo2 framework consumes over 40% of memory, and the CPU and resource consumption from address pushes is also very high, impacting normal business calls.
Why does this problem occur? We can illustrate why applications encounter capacity issues easily in the interface-level address model using a specific provider example. In the cyan section, suppose we have a typical Dubbo provider application with 10 RPC services deployed across 100 machine instances. The amount of data generated by this application in the cluster will be “Number of Services * Number of Machine Instances,” or 10 * 100 = 1000 entries. The data expands from two dimensions:
- From the address perspective: 100 unique instance addresses expand 10 times.
- From the service perspective: 10 unique service metadata entries expand 100 times.
Proposal
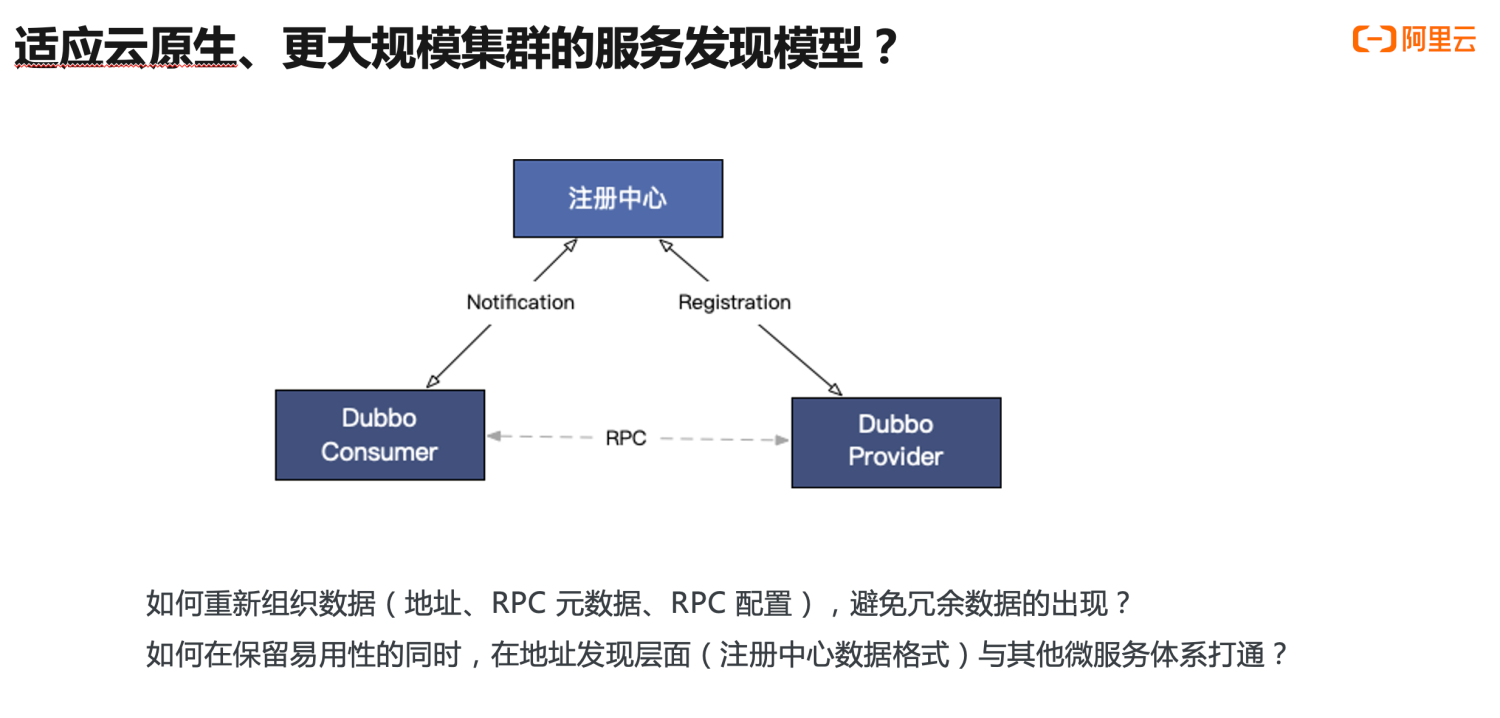
In the face of this problem, under the Dubbo3 architecture, we must rethink two questions:
- How to reorganize URL address data while retaining usability and functionality, avoiding redundant data so that Dubbo3 can support larger-scale horizontal expansion?
- How to integrate address discovery with other microservice systems such as Kubernetes and Spring Cloud?

The design of Dubbo3’s application-level service discovery solution essentially revolves around the two issues mentioned above. The basic idea is that the aggregation elements on the address discovery link, previously referenced as keys, are adjusted from service to application, which is the origin of its name, application-level service discovery. In addition, the content of data synchronized by the registration center has been streamlined significantly, retaining only the core IP and port address data.
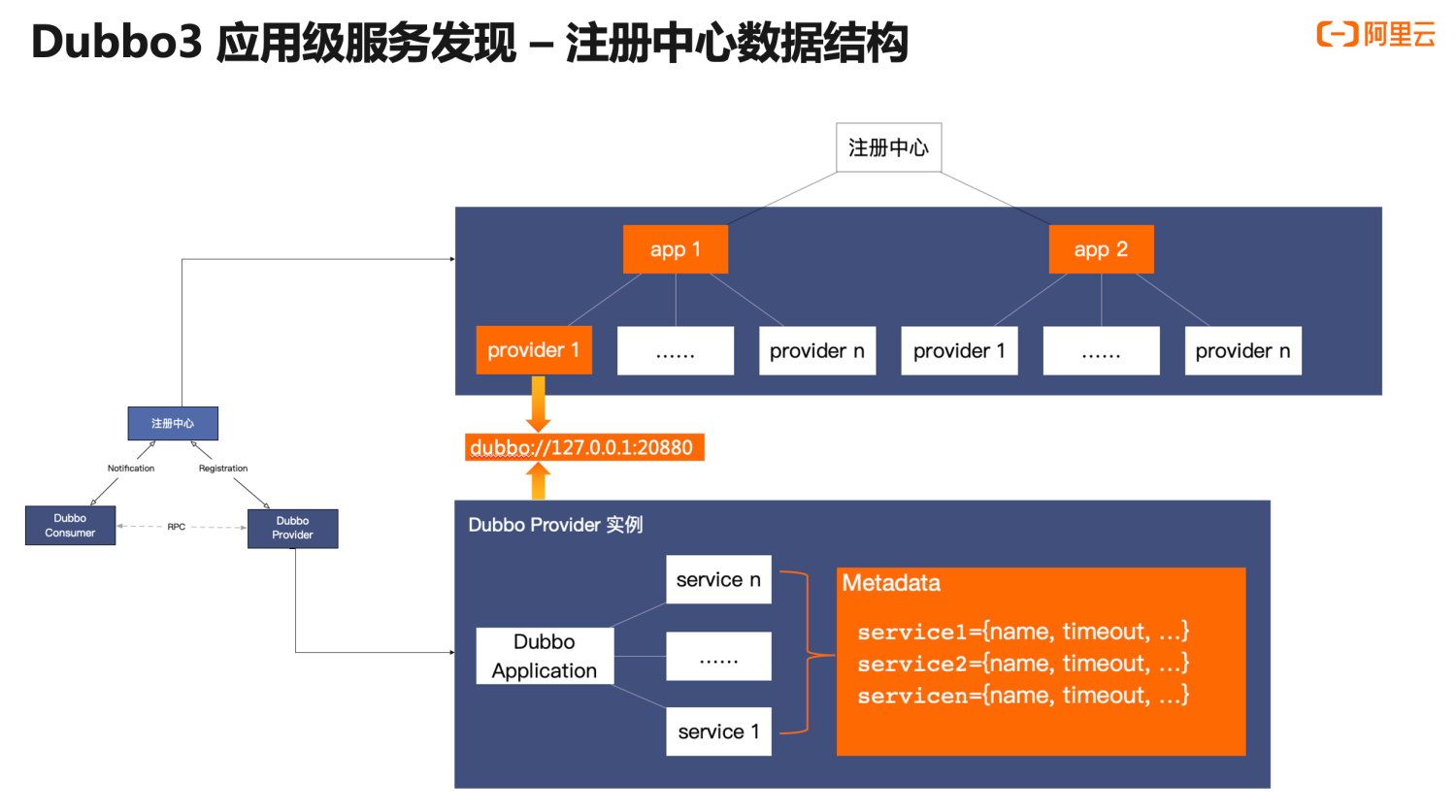
This is a detailed analysis of the internal data structure for upgraded application-level address discovery. Compared to the previous interface-level address discovery model, we primarily focus on the changes in the orange section. First, on the provider instance side, instead of each RPC Service registering a separate address data entry, a provider instance will only register one address with the registration center. On the registration center side, addresses are aggregated at the application name level, and under each application name node is the streamlined provider instance address;

The aforementioned adjustments in application-level service discovery simultaneously achieve a reduction in the size and total quantity of address data. However, this also brings new challenges: we lose the foundation of usability and functionality emphasized in Dubbo2 because the transmission of metadata has been streamlined, making it difficult to precisely control the behavior of individual services.
To address this, Dubbo3’s solution is to introduce a built-in MetadataService. Instead of centralized pushing, it transitions to a point-to-point pull model from Consumer to Provider. In this model, the volume of metadata transmission data will no longer be an issue, allowing for the expansion of more parameters and governance data.
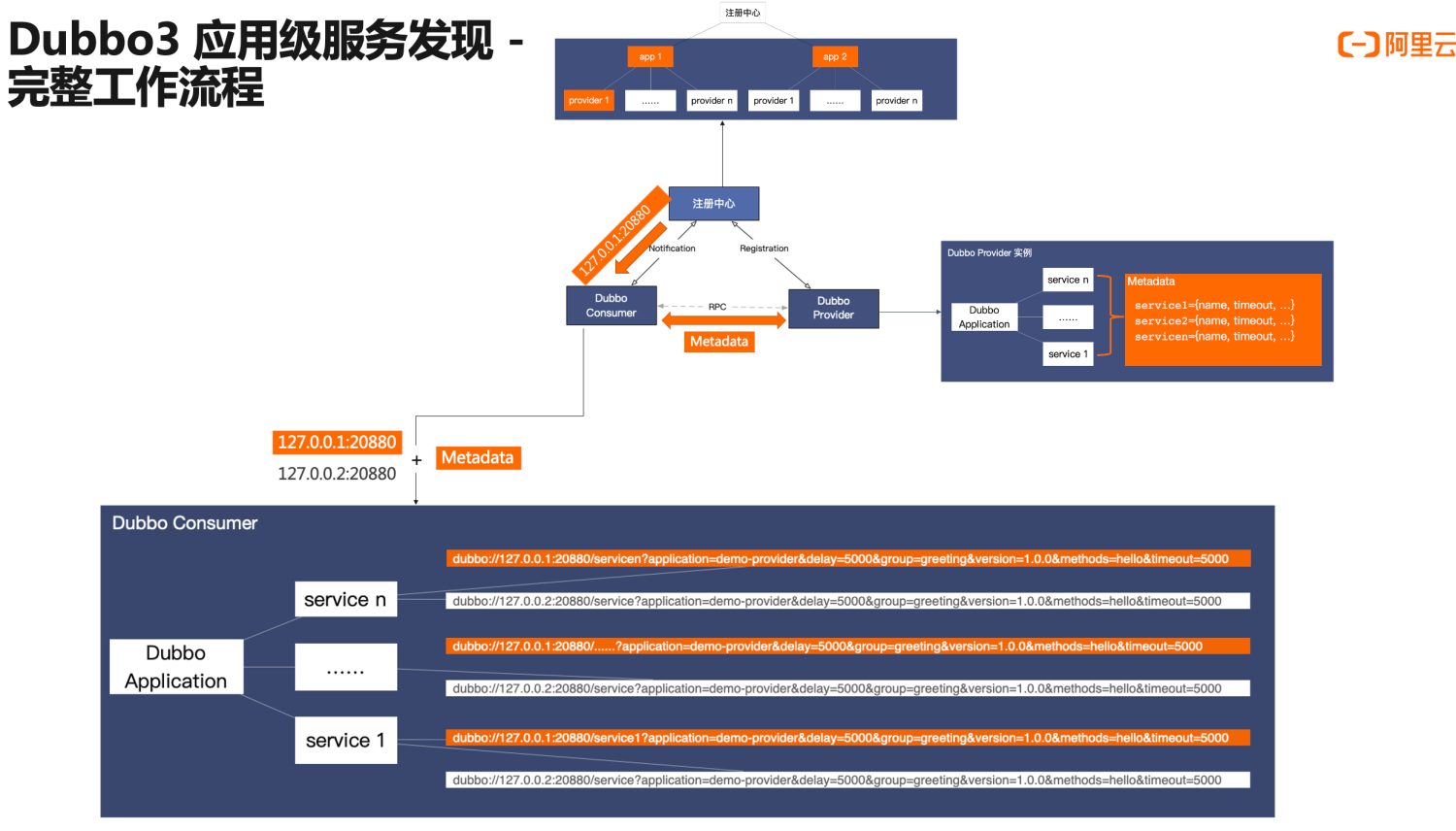
Here we focus on the address subscription behavior of the consumer. The consumer reads address data in two steps: first, receiving the streamlined addresses from the registration center, and then calling the MetadataService to read the metadata information from the opposite end. Upon receiving these two data parts, the consumer aggregates the address data and ultimately restores the URL address format similar to Dubbo2 during runtime. Thus, the application-level address model balances performance in address transmission with functionality in operation.
That concludes the background and working principle of application-level service discovery. Next, we will see how Ele.me upgraded to Dubbo3, especially the application-level service discovery process.